

Introduction:
Machine Learning models learn patterns from data. But how does a model actually learn?
The answer lies in parameters.
Parameters are one of the most important concepts in Machine Learning, and understanding
them makes it much easier to understand how models work.
Parameters are the core elements that allow a machine learning model to learn from data. They directly influence how input data is mapped to output predictions. Without parameters, a
machine learning model would not be able to learn or make decisions.
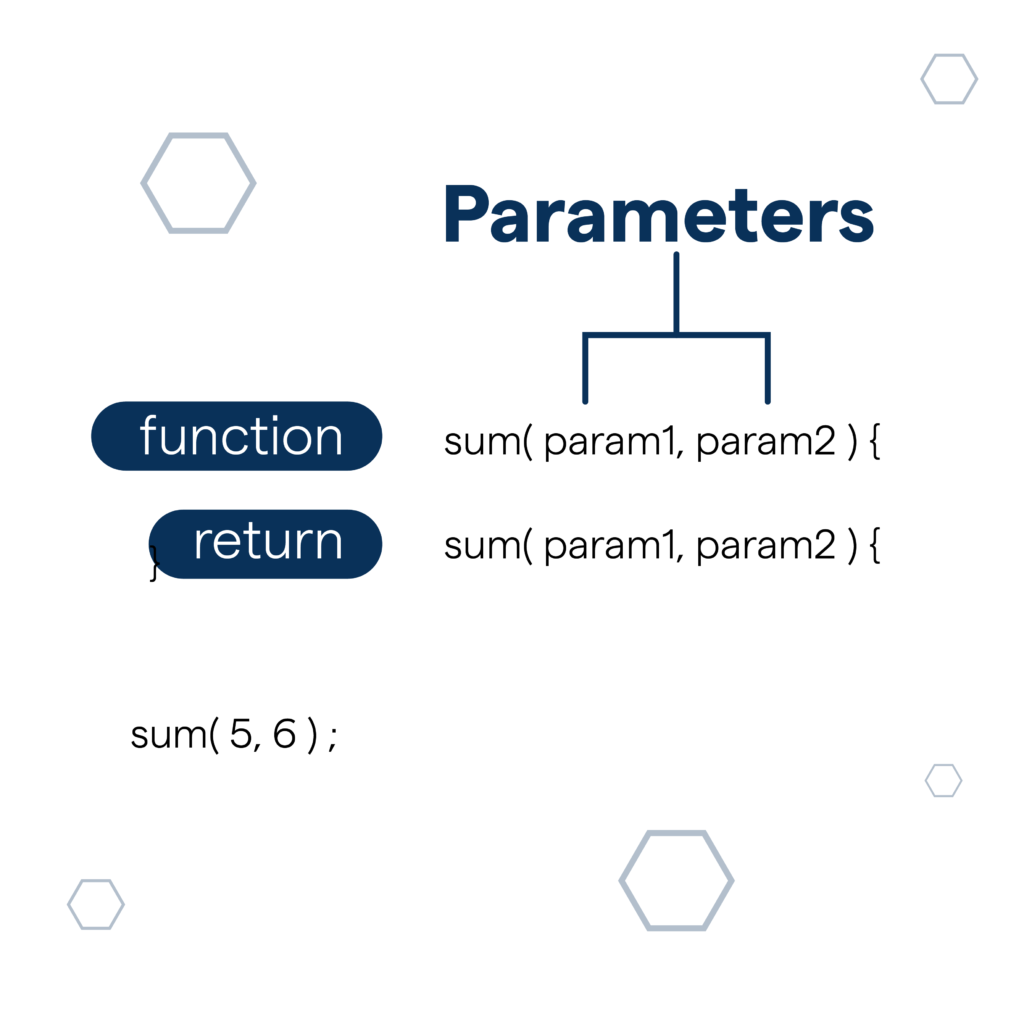
Parameters are the values passed into a function to perform a specific task. They help functions become flexible and reusable by allowing different inputs each time the function is called. In the example shown, sum(param1, param2) takes two parameters and processes them to produce a result. When values like sum(5, 6) are provided, the function uses those parameters to calculate the output. Parameters are essential in programming because they improve code efficiency, readability, and reusability.
What Are Parameters?
Parameters are the internal values of a machine learning model that are learned from training
data.
They control how the input data is transformed into output predictions.
👉 In simple words:
Parameters are the “knowledge” a model gains during training
Simple Real-Life Analogy:
Think of learning to cook a dish:
● Ingredients → Training data
● Recipe → Model
● Salt, spice quantity → Parameter
If you adjust salt and spices properly, the dish tastes good.
Similarly, when parameters are adjusted correctly, the model gives accurate predictions
In Machine Learning, parameters are internal variables of a model whose values are
learned automatically from the training data during the learning process.
They define the behavior and performance of the model.
Types of Parameters:

1.Formal parameter:
Formal parameters, also known as formal arguments, are placeholders defined in the
function signature or declaration. They represent the data that the function expects to
receive when called. Formal parameters serve as variables within the function’s scope
and are used to perform operations on the input data.
Syntax of Formal parameters:
Below is the syntax for Formal parameters:
// Here, ‘name’ is the formal parameter
function gfgFnc (name) {
// Function body
}
2.Actual parameter:
Actual parameters, also called actual arguments or arguments, are the values or
expressions provided to a function or method when it is called. They correspond to the
formal parameters in the function’s definition and supply the necessary input data for
the function to execute. Actual parameters can be constants, variables, expressions, or
even function calls.
Syntax of Actual parameters:
Below is the syntax for Actual parameters:
function gfgFnc(name) {
// Function body
}
// Actual Parameter
gfgFnc(“Geek”);
Parameters in Different ML Models:
Linear Regression:
● Parameter: slope (w), intercept (b)
● Learns linear relationship
Logistic Regression:
● Parameters: weights and bias
● Output is a probability
Decision Trees:
● Parameters: split thresholds and feature selection
● Learned from data distribution
Support Vector Machines:
● Parameters: support vectors and weights
Neural Networks:
● Parameters: weights and biases across layers
● Can range from thousands to billions
Mathematical View of Parameters:
A model function can be written as:
y^=f(x;θ)\hat{y} = f(x; \theta)y^=f(x;θ)
Where:
● xxx = input data
● y^\hat{y}y^ = predicted output
● θ\thetaθ = model parameters
Training aims to find the optimal θ\thetaθ that minimizes error.
Parameters vs Hyperparameters:
This is a common confusion
| Parameters | Hyperparameters |
|---|---|
| Learned automatically from data | Humans manually set pannuvanga |
| Training time-la update aagum | Training start panna munnadi fix pannuvanga |
| Model internal values | Model configuration settings |
| Example: Weights, Bias | Example: Learning rate, Batch size |
👉 Hyperparameters = configured
Parameter Learning Process:
- Initialize parameters randomly
- Pass data through the model
- Compute loss (error)
- Update parameters using optimization algorithms
- Repeat until convergence
Common optimizers:
● Gradient Descent
Parameter Learning Process:
1.Initialize parameters randomly
2.Pass data through the model
3.Compute loss (error)
4.Update parameters using optimization algorithms
5.Repeat until convergence
Common optimizers:
● Gradient Descent
● Adam
● RMSprop
Parameters and Loss Function Relationship:
The loss function measures how wrong the predictions are.
Parameters are adjusted to:
● Reduce loss
● Improve accuracy
● Generalize better to unseen data
Why Parameters Are Important:
✔ Decide model accuracy
✔ Store learned patterns
✔ Affect model complexity
✔ More parameters → more expressive power (but risk of overfitting)
Too Few vs Too Many Parameters:
● Too few parameters → Underfitting (model is too simple)
● Too many parameters → Overfitting (model memorizes data)
A good model finds the right balance.
Parameters in Modern AI Models:
| Model | Approx. Parameters |
|---|---|
| Logistic Regression | Few parameters |
| CNN (Convolutional Neural Network) | Millions |
| BERT | ~110 million |
| GPT Models | Billions+ |
Large Language Models work well because they have huge numbers of parameters trained
on massive data.
Key Takeaway:
Parameters are the learnable values inside a machine learning model that store
what the model has learned from data.
Without parameters, a model cannot learn or make intelligent predictions.




