

Introduction:
In the world of Artificial Intelligence (AI) and Machine Learning (ML), the term embedding is very important. If you are working with Natural Language Processing (NLP), deep learning, or recommendation systems, understanding embeddings is essential.
What is Embedding?
An embedding is a way to convert data (like words, sentences, images, or users) into numerical vectors (arrays of numbers) so that machines can understand and process them.
In simple words:
Embedding = Converting real-world data into meaningful numbers.
Since machine learning models only understand numbers, embeddings help represent complex data in a mathematical form while keeping important relationships intact.
Why Do We Need Embeddings?
Computers don’t understand text like humans.
For example:
- “King” and “Queen” are related words.
- “Cat” and “Dog” are similar animals.
- “Apple” and “Car” are completely different.
If we simply assign random numbers to these words, the model won’t understand their relationships.
Embeddings solve this problem by:
- Placing similar words closer together in vector space
- Placing unrelated words farther apart
- Preserving semantic meaning
How Do Embeddings Work?
Each word (or data item) is represented as a vector in a high-dimensional space.
Example:
King → [0.21, -0.45, 0.78, 0.10]
Queen → [0.19, -0.40, 0.80, 0.12]
These vectors are mathematically close, meaning the words are related.
A famous example:
King − Man + Woman ≈ Queen
This shows embeddings capture meaningful relationships.
What is Embedding? (Advanced & In-Depth Content)
Embeddings are one of the most powerful concepts in modern Artificial Intelligence (AI) and Machine Learning (ML). They act as a bridge between human-understandable data (text, images, audio, users, products) and machine-understandable numerical representations.
In this extended guide, we’ll go deeper into:
- How embeddings are trained
- Mathematical intuition
- Types of embedding architectures
- Vector databases
- Role in Generative AI
- Real-world industry use cases
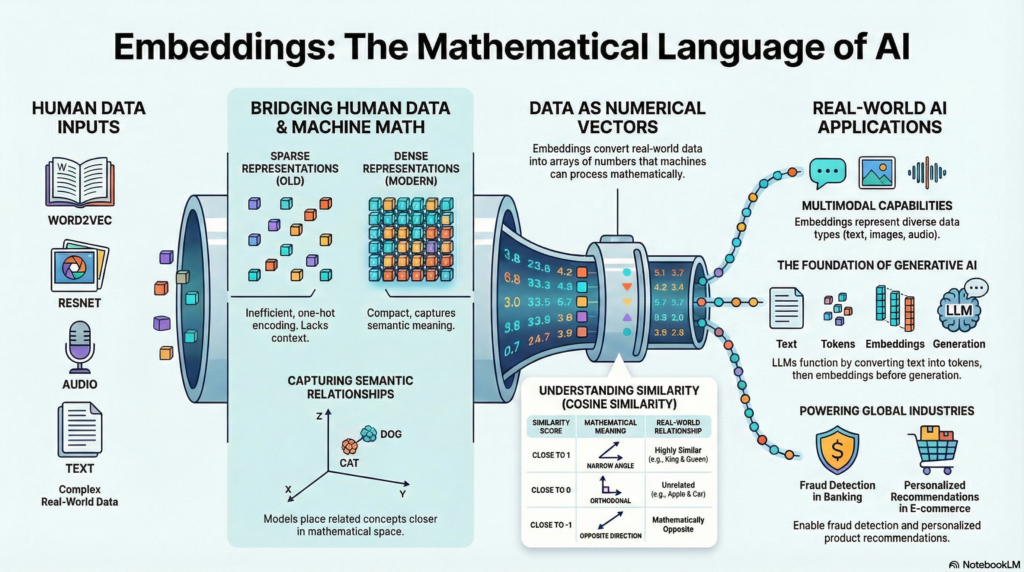
Types of Embeddings:
1.Word Embeddings:
These represent individual words as vectors.
Popular word embedding models:
- Word2Vec
- GloVe
- FastText
These models learn word meanings from large text datasets.
2.Sentence Embeddings:
Instead of individual words, entire sentences are converted into vectors.
Example:
- “I love machine learning.”
- “AI is my passion.”
If meanings are similar, vectors will be close.
Popular models:
- BERT
- Sentence-BERT
3.Image Embeddings:
Images can also be converted into vectors.
Deep learning models like:
- ResNet
- VGGNet
extract features from images and represent them numerically.
1. The Core Idea Behind Embeddings:
At its heart, an embedding maps discrete objects (like words or IDs) into a continuous vector space.
Formally:
An embedding is a function
f(x) → ℝⁿ
That means:
- Input: word, sentence, image, or user ID
- Output: a dense vector of n dimensions
Instead of sparse representations like one-hot encoding, embeddings use dense vectors, which are more compact and meaningful.
2. From One-Hot Encoding to Dense Embeddings:
One-Hot Encoding (Old Method)
If vocabulary size = 10,000
Word “AI” → [0,0,0,0,1,0,0,0,0…]
Problems:
- High dimensional
- Sparse (mostly zeros)
- No semantic meaning
- “Cat” and “Dog” equally distant from “Car”
Dense Embeddings (Modern Method)
Word “AI” → [0.24, -0.11, 0.89, 0.02, …]
Advantages:
- Lower dimensional (e.g., 100–1024 dimensions)
- Captures semantic similarity
- Learns context from data
3. How Are Embeddings Trained?
Embeddings are not manually assigned. They are learned automatically during model training.
Word-Level Training Example:
Models like:
- Word2Vec
- GloVe
- FastText
learn embeddings using context prediction.
Two Main Word2Vec Techniques:
- CBOW (Continuous Bag of Words)
Predicts a word from surrounding context. - Skip-Gram
Predicts surrounding words from a target word.
Over time, words used in similar contexts get similar vectors.
4. Contextual Embeddings (Next Generation)
Earlier embeddings gave one vector per word.
Example:
- “Bank” (river bank)
- “Bank” (financial bank)
Both had same vector
Modern transformer models like:
- BERT
- GPT
produce contextual embeddings.
Meaning:
- “Bank” in finance → different vector
- “Bank” near river → different vector
This revolutionized NLP.
5. Mathematical Intuition: Similarity Measurement
Embeddings allow similarity comparison using:
🔸 Cosine Similarity
Measures angle between vectors.
- Close to 1 → very similar
- Close to 0 → unrelated
- Close to -1 → opposite
This is heavily used in:
- Semantic search
- Recommendation engines
Question answering systems
6.Sentence & Document Embeddings
Instead of individual words, we can embed entire sentences or documents.
Popular models:
● Sentence-BERT
● Universal Sentence Encoder
Applications:
● Duplicate detection
● Chatbot intent matching
● Resume screening
● Legal document comparison
7.Embeddings in Generative AI
Large Language Models (LLMs) first convert text into embeddings.
Pipeline:
- Input text
- Convert to tokens
- Convert tokens to embeddings
- Process via attention layers
- Generate output
Without embeddings, transformer models cannot function.
This is foundational in:
● Chatbots
● AI assistants
● Code generators
● Content creation tools
8.Vector Databases & Semantic Search
Once embeddings are created, they are stored in vector databases.
Popular vector databases:
● Pinecone
● Weaviate
● Milvus
These allow:
● Fast similarity search
● Nearest neighbor retrieval
● Real-time recommendation
This powers modern semantic search engines.
9.Real-World Industry Use Cases
Banking:
● Fraud detection
● Customer behavior clustering
● Credit risk modeling
E-commerce:
● Product recommendation
● Personalized ads
● Similar product search
Streaming Platforms:
● Movie recommendation
● User preference modeling
Healthcare:
● Patient similarity analysis
● Medical report comparison
Social Media:
● Content recommendation
● Spam detection
● Toxic comment filtering
10.Types of Embeddings Beyond Text
Image Embeddings:
Extracted using CNN models like:
● ResNet
Used in:
● Face recognition
● Image search
● Object detection
Audio Embeddings:
Used in:
● Speech recognition
● Speaker identification
● Music recommendation
Graph Embeddings:
Used in:
● Social network analysis
● Fraud detection networks
● Knowledge graphs
11.Advantages of Embeddings
✔ Capture deep semantic meaning
✔ Reduce high-dimensional sparse data
✔ Enable similarity search
✔ Improve ML model accuracy
✔ Essential for modern AI systems
12. Challenges of Embeddings
- Bias in training data
- High computational cost
- Interpretability issues
- Storage requirements for large-scale systems
Final Conclusion
Embeddings are the backbone of modern AI systems. They convert real-world data into
meaningful numerical representations while preserving relationships and structure.
From search engines to chatbots, from fraud detection to recommendation systems —
embeddings power the intelligence behind today’s AI revolution.
If AI is the brain, embeddings are the language it thinks in.




