
Modern organizations generate massive volumes of data every day. To process and analyze this data efficiently, companies need scalable and automated data pipelines. Traditional infrastructure-heavy pipelines can be expensive and difficult to maintain. This is where serverless data pipelines become extremely valuable.
In this article, we will explore how to build serverless data pipelines using AWS Glue, Amazon Athena, and CI/CD automation tools like GitHub Actions. By the end of this guide, you will understand how to design, deploy, and automate a modern serverless data pipeline architecture.
What is a Serverless Data Pipeline?
A serverless data pipeline is a data processing workflow where infrastructure management is handled automatically by the cloud provider. Engineers focus on writing transformation logic instead of provisioning servers.
Key characteristics of serverless pipelines include:
- No server management
- Automatic scaling
- Pay-per-use pricing
- Built-in fault tolerance
Services such as AWS Glue and Amazon Athena enable organizations to build fully serverless data analytics platforms.
Why Use Serverless Architecture for Data Pipelines?
Serverless architectures have become popular in modern data engineering and analytics systems.
Key Benefits
1. Reduced Infrastructure Management
Developers no longer need to manage clusters or compute resources. Cloud services automatically scale based on workload.
2. Cost Efficiency
You only pay for the resources consumed during query execution or ETL processing.
3. Faster Development
Serverless services allow teams to build pipelines quickly without worrying about infrastructure setup.
4. Scalability
Serverless pipelines can process large datasets without manual scaling.
These advantages make serverless architectures ideal for data lakes, analytics platforms, and machine learning pipelines.
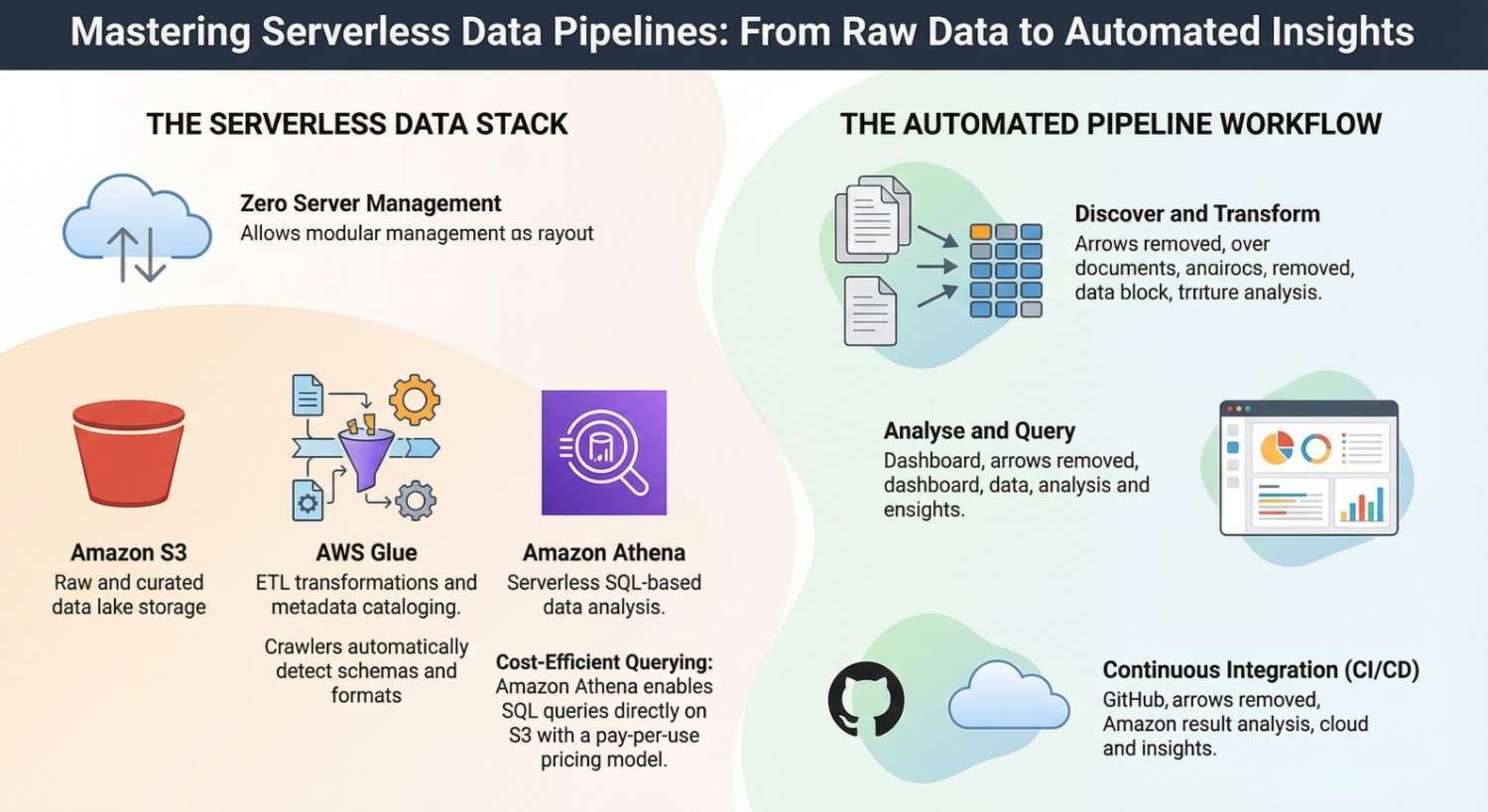
Core Components of a Serverless Data Pipeline
A typical serverless data pipeline architecture consists of several key services.
Data Storage
Most serverless pipelines store raw data in cloud storage services like Amazon S3.
Data Processing
ETL transformations are handled by AWS Glue, which processes and prepares data for analysis.
Data Query Layer
Amazon Athena enables SQL-based querying directly on data stored in S3.
Automation Layer
CI/CD tools such as GitHub Actions automate testing and deployment of pipeline code.
Together, these services form a fully automated serverless data platform.
Architecture Overview
A typical serverless data pipeline using Glue and Athena follows this workflow:
- Raw data is uploaded to Amazon S3.
- A Glue crawler scans the data and updates the data catalog.
- Glue ETL jobs transform and clean the data.
- Processed data is stored in curated datasets.
- Athena queries analyze the data for reporting and insights.
- CI/CD pipelines automate deployment and testing.
This architecture is widely used in modern cloud data lake solutions.
Step 1: Store Data in a Data Lake
The foundation of a serverless pipeline is a data lake.
Data is typically stored in structured directories such as:
s3://company-data-lake/
├── raw/
├── processed/
└── analytics/
Benefits of data lakes:
- Store structured and unstructured data
- Support large-scale analytics
- Integrate easily with serverless tools
This storage layer enables efficient querying using Amazon Athena.
Step 2: Discover Data Using Glue Crawlers
Before running queries, datasets must be registered in a metadata catalog.
**AWS Glue crawlers automatically scan data stored in S3 and detect:
- Schema structure
- Data formats
- Table definitions
The crawler then updates the AWS Glue Data Catalog, which acts as the metadata layer for analytics tools.
Step 3: Build ETL Transformations with Glue
Once data is cataloged, ETL jobs transform raw datasets into analytics-ready tables.
Glue supports transformations using:
- Python
- PySpark
- Spark SQL
Typical transformations include:
- Data cleansing
- Aggregations
- Format conversion (JSON → Parquet)
- Partitioning for performance optimization
Using AWS Glue, engineers can build scalable ETL pipelines without managing infrastructure.
Step 4: Query Data Using Athena
After transformation, datasets become available for analysis.
Amazon Athena allows analysts and engineers to run SQL queries directly on data stored in S3.
Example query:
SELECT customer_id, SUM(total_amount) FROM sales_data GROUP BY customer_id;Advantages of Athena:
- Serverless SQL queries
- No database setup
- Integration with Glue Data Catalog
Athena is widely used in interactive data analytics and business intelligence workloads.
Step 5: Implement CI/CD for Data Pipelines
To ensure reliable deployments, data teams implement CI/CD pipelines for ETL workflows.
CI/CD automation enables:
- Version control for ETL scripts
- Automated testing
- Continuous deployment
Tools like GitHub Actions automate pipeline workflows whenever code changes are pushed to the repository.
Example CI/CD Workflow
A CI/CD pipeline for serverless data pipelines typically includes:
Code Commit
Engineers push ETL scripts to GitHub.
Continuous Integration
Automated checks validate the code:
- Unit testing
- Syntax validation
- Dependency checks
Continuous Deployment
Deployment scripts update:
- Glue ETL jobs
- Data catalog configurations
- Infrastructure settings
This automation ensures consistent and reliable pipeline deployments.
Best Practices for Serverless Data Pipelines
Building scalable pipelines requires following best practices.
Partition Data for Faster Queries
Partitioning improves performance in Amazon Athena.
Example partition structure:
sales/year=2026/month=03/day=05/
Partitioning reduces the amount of data scanned during queries.
Convert Data to Columnar Formats
Formats like Parquet and ORC improve performance and reduce query costs.
These formats are optimized for analytics workloads.
Automate Infrastructure
Define infrastructure using tools such as:
- Terraform
- AWS CloudFormation
Infrastructure as Code ensures reproducible environments.
Monitor Pipeline Performance
Monitoring tools help track:
- ETL job failures
- Query performance
- Data processing costs
Observability is critical for maintaining production-grade data pipelines.
Real-World Use Cases
Serverless data pipelines are widely used across industries.
Business Intelligence
Companies analyze sales and customer behavior using Athena queries.
Log Analytics
Serverless pipelines process application logs for monitoring and security analysis.
Data Lake Analytics
Organizations build centralized data lakes for cross-department analytics.
Using AWS Glue and Amazon Athena, companies can process large datasets efficiently.
Benefits of Serverless Data Pipelines
Adopting serverless pipelines provides several advantages.
- Faster data processing workflows
- Lower operational costs
- Automated scaling
- Improved reliability
- Simplified infrastructure management
These benefits help organizations build scalable cloud-native data platforms.
Conclusion
Serverless architectures are transforming the way organizations build and manage data pipelines. By combining AWS Glue for ETL processing, Amazon Athena for analytics queries, and CI/CD automation with GitHub Actions, teams can build powerful, scalable, and cost-efficient data pipelines.
Implementing CI/CD practices ensures that data pipelines remain reliable, maintainable, and easy to scale as data volumes grow.
As more organizations adopt cloud-native data engineering practices, serverless pipelines will continue to play a key role in building modern analytics platforms.
- If you want to explore AWS, start your training here.
- If you want to explore DevOps, start your training here.




