
Continuous Delivery (CD) has been around for over a decade, promising faster releases, higher quality software, and happier teams. Yet, in 2026, many organizations still struggle to make it work effectively. Pipelines break, deployments fail, teams bypass processes, and the dream of seamless delivery often turns into operational chaos.
So why does Continuous Delivery still fail and more importantly, how can teams fix it?
Let’s dig deep.
The Promise vs. The Reality
At its core, Continuous Delivery is simple: keep your codebase in a deployable state at all times. Automate everything from build to test to deployment, and release software frequently with minimal risk.
In reality, many teams:
- Have brittle pipelines that break frequently
- Spend hours debugging deployments
- Lack confidence in automated tests
- Delay releases despite “having CD”
The gap between having a pipeline and achieving true Continuous Delivery is where most failures happen.
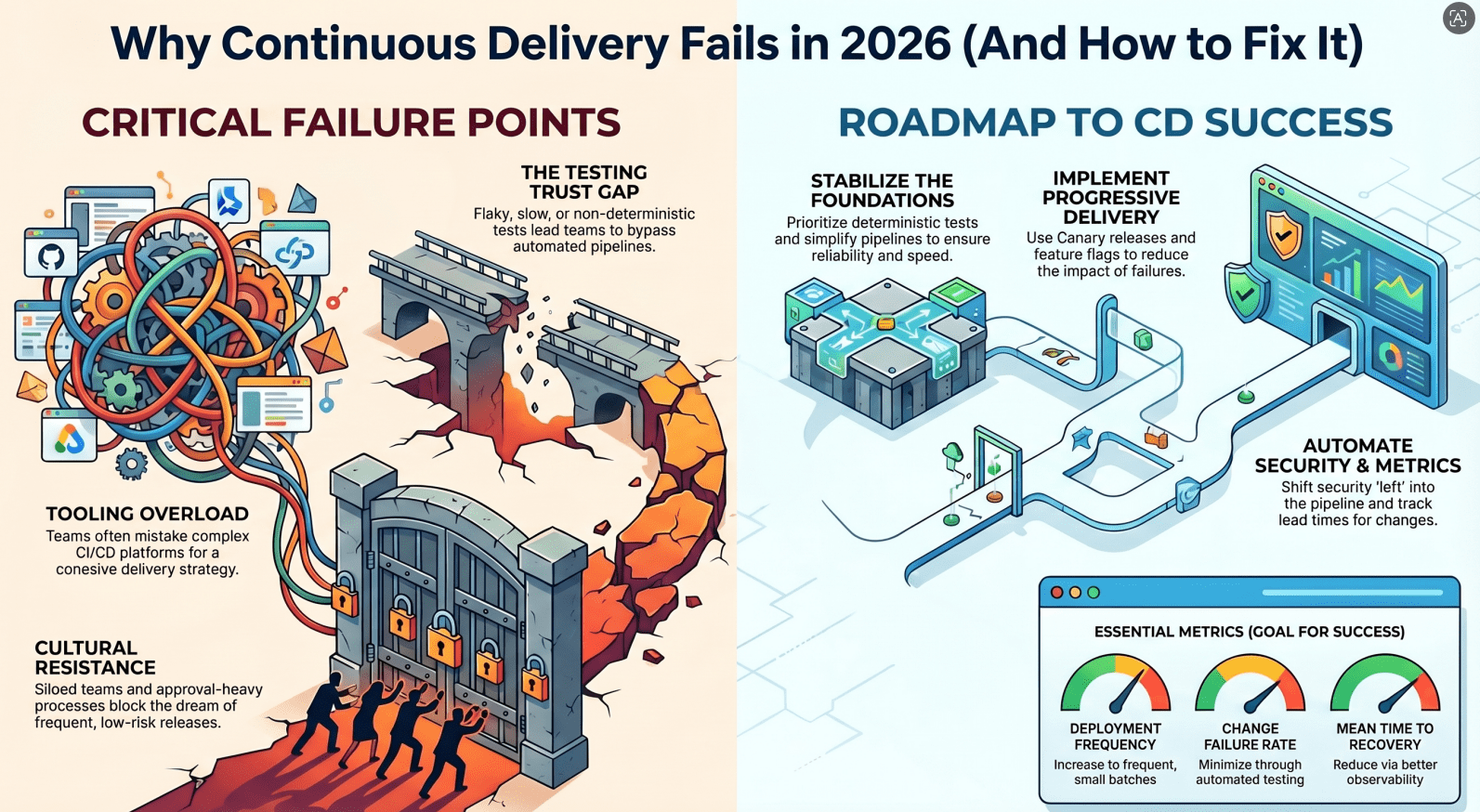
1. Tooling Overload (Mistaking Tools for Strategy)
The Problem
Teams often believe adopting the right tools automatically leads to success. They stack CI/CD platforms, orchestration tools, observability systems, and security scanners without a cohesive strategy.
The result?
- Fragmented workflows
- Steep learning curves
- Integration issues
- Increased cognitive load on developers
Instead of simplifying delivery, tools make it more complex.
The Fix
Start with principles, not tools:
- Define your delivery goals (speed, reliability, compliance)
- Map your value stream
- Choose tools that support not dictate your workflow
Focus on:
- Fewer tools, better integration
- Standardized pipelines
- Clear ownership of tooling
2. Weak Testing Foundations
The Problem
Automated testing is the backbone of Continuous Delivery but many teams rely on:
- Flaky tests
- Slow test suites
- Poor test coverage
When tests fail unpredictably, developers lose trust in the pipeline. Once trust is gone, teams start bypassing checks, defeating the purpose of CD.
The Fix
Invest in test reliability:
- Prioritize deterministic tests
- Separate fast unit tests from slower integration tests
- Continuously monitor flaky tests and eliminate them
Adopt a testing pyramid:
- Many fast unit tests
- Fewer integration tests
- Minimal end-to-end tests
Also:
- Run tests in parallel
- Use test data management strategies
- Track test performance metrics
3. Cultural Resistance
The Problem
Continuous Delivery isn’t just a technical shift it’s a cultural one. Many organizations still operate with:
- Siloed teams (Dev vs Ops vs QA)
- Fear of production failures
- Approval-heavy processes
This leads to:
- Delayed deployments
- Manual gates
- Lack of ownership
The Fix
Build a delivery culture:
- Encourage shared ownership of production
- Normalize small, frequent releases
- Replace approval gates with automated checks
Leaders should:
- Reward experimentation
- Accept controlled failures as learning opportunities
- Promote transparency
Without cultural alignment, even the best pipelines fail.
4. Over-Engineering Pipelines
The Problem
Ironically, many CD pipelines become too complex:
- Dozens of stages
- Conditional logic everywhere
- Overly strict gates
This creates:
- Long pipeline execution times
- Difficult debugging
- High maintenance overhead
Complex pipelines slow down delivery instead of accelerating it.
The Fix
Simplify aggressively:
- Keep pipelines lean and focused
- Remove unnecessary stages
- Optimize for speed and clarity
Best practices:
- Aim for pipeline completion within minutes, not hours
- Use reusable pipeline templates
- Avoid premature optimization
Remember: a simple pipeline that works is better than a complex one that breaks.
5. Lack of Observability
The Problem
Many teams deploy code but lack visibility into:
- System performance
- User impact
- Deployment health
Without observability, teams:
- Discover issues too late
- Roll back blindly
- Lose confidence in deployments
The Fix
Integrate observability into your CD process:
- Monitor key metrics (latency, error rates, throughput)
- Use logging and tracing for debugging
- Set up real-time alerts
Also:
- Tie deployments to metrics
- Automatically halt rollouts if anomalies are detected
- Use dashboards to visualize system health
Continuous Delivery without feedback is just continuous risk.
6. Ignoring Deployment Strategies
The Problem
Many teams still deploy using “all-at-once” strategies. This increases risk and makes failures catastrophic.
A single bad release can:
- Bring down systems
- Impact all users
- Require urgent rollbacks
The Fix
Adopt progressive delivery:
- Blue-green deployments
- Canary releases
- Feature flags
Benefits:
- Reduced blast radius
- Safer experimentation
- Faster recovery
Gradual rollouts turn deployments from high-risk events into controlled processes.
7. Poor Environment Parity
The Problem
“It works on my machine” is still alive in 2026.
Differences between development, staging, and production environments lead to:
- Unexpected bugs
- Deployment failures
- Configuration issues
The Fix
Ensure environment consistency:
- Use containerization
- Define infrastructure as code
- Automate environment provisioning
Also:
- Minimize differences between environments
- Use production-like test environments
- Regularly validate configurations
Consistency reduces surprises and surprises kill CD.
8. Security Bottlenecks
The Problem
Security is often treated as a final gate rather than an integrated process. This leads to:
- Delayed releases
- Last-minute vulnerabilities
- Friction between teams
The Fix
Shift security left:
- Integrate security checks into pipelines
- Automate vulnerability scanning
- Use policy-as-code
Make security:
- Continuous
- Automated
- Developer-friendly
Security should accelerate delivery not block it.
9. Lack of Clear Metrics
The Problem
Many teams adopt CD without measuring its effectiveness. Without metrics, it’s impossible to know:
- Whether delivery is improving
- Where bottlenecks exist
- How reliable the system is
The Fix
Track key delivery metrics:
- Deployment frequency
- Lead time for changes
- Change failure rate
- Mean time to recovery (MTTR)
Use metrics to:
- Identify weak points
- Drive improvements
- Align teams around goals
What gets measured gets improved.
10. Scaling Problems
The Problem
What works for a small team often breaks at scale. Large organizations face:
- Complex dependencies
- Multiple teams and services
- Coordination challenges
This leads to:
- Slower pipelines
- Increased failures
- Communication gaps
The Fix
Design for scale:
- Decouple services
- Use modular architectures
- Enable team autonomy
Also:
- Standardize practices across teams
- Invest in platform engineering
- Provide self-service tooling
Scaling CD requires intentional design not just bigger pipelines.
The Real Root Cause: Misunderstanding Continuous Delivery
At a deeper level, most failures come from misunderstanding what Continuous Delivery actually is.
It’s not:
- A tool
- A pipeline
- A checklist
It’s a system of:
- Practices
- Culture
- Automation
- Feedback loops
Organizations that treat CD as a “project” fail. Those that treat it as a continuous improvement journey succeed
A Practical Roadmap to Fix Continuous Delivery
If your CD is struggling, here’s a practical approach:
Step 1: Assess Your Current State
- Map your delivery pipeline
- Identify bottlenecks
- Gather team feedback
Step 2: Fix the Foundations
- Stabilize tests
- Simplify pipelines
- Improve environment consistency
Step 3: Build Confidence
- Increase observability
- Implement safer deployment strategies
- Reduce failure rates
Step 4: Align Culture
- Break down silos
- Encourage ownership
- Reduce manual approvals
Step 5: Optimize Continuously
- Track metrics
- Experiment with improvements
- Iterate regularly
The Future of Continuous Delivery
In 2026 and beyond, Continuous Delivery is evolving:
- AI-assisted pipelines optimize workflows
- Self-healing systems reduce failures
- Platform engineering abstracts complexity
But the fundamentals remain unchanged:
- Simplicity
- Automation
- Feedback
- Culture
Teams that focus on these principles will succeed regardless of tools or trends.
Final Thoughts
Continuous Delivery still fails in 2026 not because the idea is flawed, but because its implementation often is.
The good news?
Every failure point has a fix.
By focusing on:
- Strong foundations
- Simplicity over complexity
- Culture over tools
- Feedback over assumptions
…you can turn Continuous Delivery from a frustrating bottleneck into a true competitive advantage.
The goal isn’t just to deploy faster.
It’s to deliver value reliably, safely, and continuously.
And that’s still worth striving for.
- Ready to level up your DevOps skills? Click here.




