

Self-Attention Explained: The Brain
Behind Modern AI Models
In recent years, Artificial Intelligence has made remarkable progress in understanding human
language. From chatbots to language translation and text generation, models today can grasp
context, meaning, and relationships between words with impressive accuracy. At the heart of
this breakthrough lies a powerful idea called Self-Attention.
This blog explains what self-attention is, how it works, and why it is so important in modern deep
learning models like Transformers.
What Is Self-Attention?
Self-attention is a mechanism that allows a model to focus on different parts of an input
sequence when processing each element of that sequence.
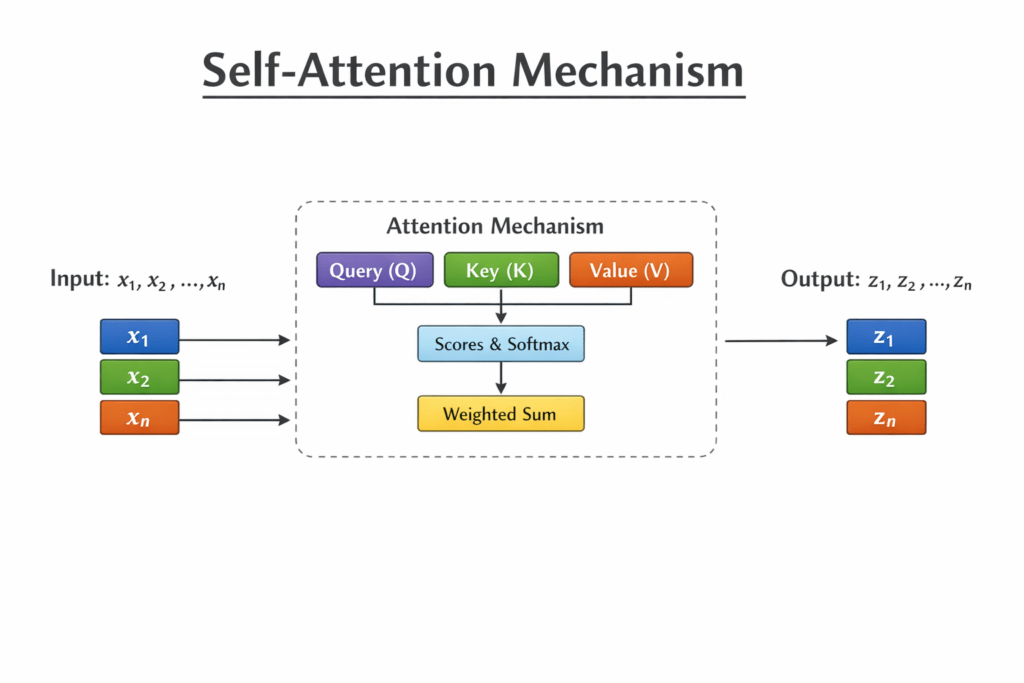
In simpler terms, it helps a model decide:
“Which other words in this sentence are important for understanding this word?”
Unlike traditional models that read text word by word, self-attention looks at the entire sentence
at once and learns the relationships between all words simultaneously.
Why Do We Need Self-Attention?
Consider the sentence:
“The student said he was tired.”
To understand the meaning correctly, the model must know that “he” refers to “the student.”
Words that matter for understanding may not always be close together.
Older models like RNNs struggled with such long-range dependencies. Self-attention solves this
problem by allowing every word to directly connect with every other word in the sentence.
How Self-Attention Works:
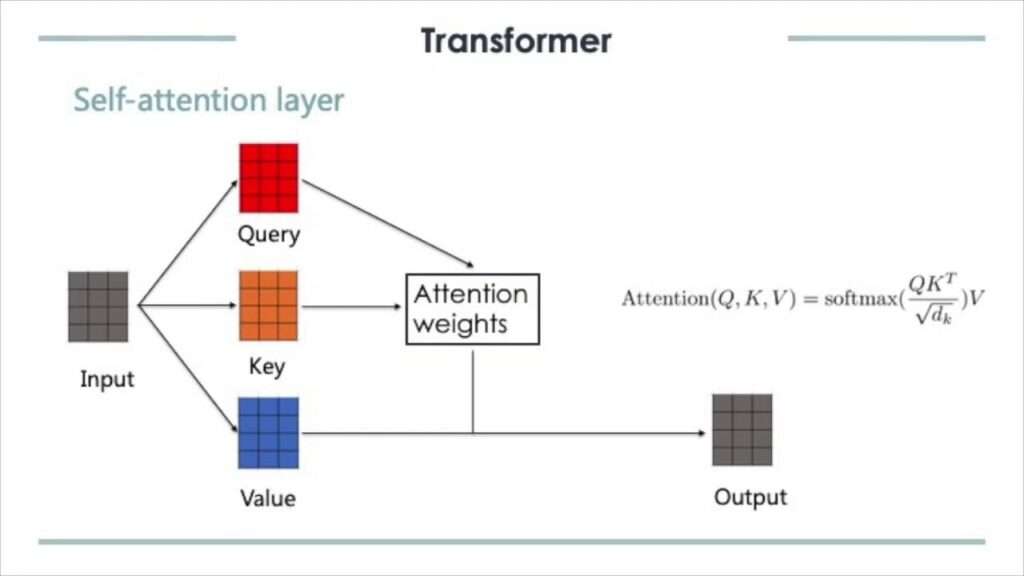
For each word in a sentence, the model creates three vectors:
● Query (Q): What this word is looking for
● Key (K): What this word offers
● Value (V): The actual information carried by the word
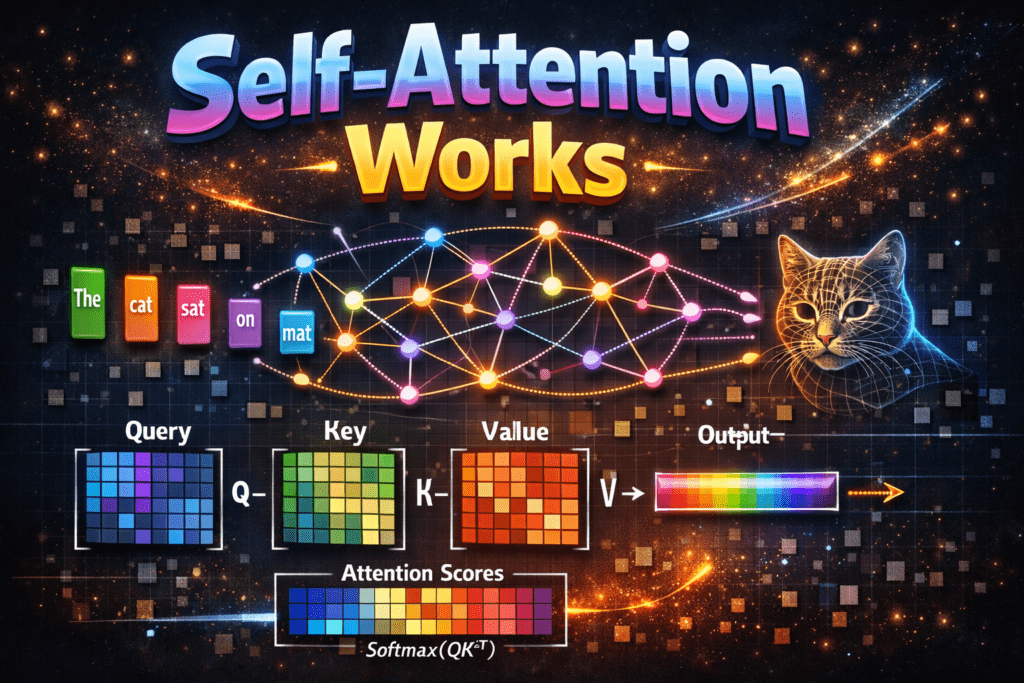
Step-by-step process:
- Each word’s Query is compared with the Keys of all words.
- These comparisons produce attention scores.
- The scores are normalized using a Softmax function.
- The normalized scores are used to weight the Values.
- The weighted values are summed to create a context-aware representation of the
word.
As a result, every word understands itself in relation to all other words in the sentence.
A Simple Example:
Sentence:
“I love artificial intelligence.”
When the model processes the word “love”, self-attention helps it focus more on:
● “I” (who loves)
● “artificial intelligence” (what is loved)
This enables the model to capture meaning, not just individual words.
Key Advantages of Self-Attention:

● Captures long-range dependencies easily
● Processes words in parallel, making training faster
● Understands context and semantics better than sequential models
● Forms the foundation of the Transformer architecture
Self-Attention in Transformers:
Self-attention is the core building block of the Transformer model, introduced in the paper
“Attention Is All You Need.”
Transformers use:
● Multi-head self-attention to capture different types of relationships
● Stacked attention layers to build deep understanding
Popular models like BERT, GPT, and T5 rely heavily on self-attention to achieve state-of-the-art
performance.
Self-Attention vs Traditional
Approaches
Overview:
Before Transformers, models used traditional sequence-based approaches like:
● RNN (Recurrent Neural Network)
● LSTM (Long Short-Term Memory)
● GRU
Self-Attention changed everything by allowing models to look at all words at once.
Same Sentence:
“The animal didn’t cross the road because it was tired.”
Self-attention learns:
● “it” → refers to animal, not road
Characteristics:
| Feature | Traditional Models |
|---|---|
| Processing | Sequential |
| Context Understanding | Limited |
| Long Sentences | Difficult |
| Parallelization | Not possible |
| Speed | Slow |
Self-Attention (Transformer Approach)
How It Works:
● Each word attends to all other words
● Learns which words are important
● Processes entire sentence at once
Same sentence:
“The animal didn’t cross the road because it was tired.”
Self-attention learns:
● “it” → refers to animal, not road
Advantages:
● Captures long-range dependencies
● Faster training
● Better understanding of context
● Highly scalable
● Foundation of BERT, GPT, Transformer
Key Technical Difference (Simple):
Traditional Models:
Word1 → Word2 → Word3 → Word4
Self-Attention:
Word1 ↔ Word2 ↔ Word3 ↔ Word4
Every word connects to every other word
Example Comparison:
Sentence:
“I went to the bank to deposit money.”
Model Understanding
Traditional May confuse “bank”
Self-Attention Links “bank” with “money”
Computational Perspective:
| Aspect | Traditional | Self-Attention |
|---|---|---|
| Time Complexity | O(n) | O(n²) |
| Parallelization | ❌ No | ✅ Yes |
| Memory | Low | Higher |
| Accuracy | Medium | High |
Real-World Impact:
Traditional Models:
● Speech recognition (older systems)
● Early chatbots
● Time-series models
Self-Attention:
● ChatGPT
● Google Translate
● Search engines
● Text summarization
Conclusion:
Self-attention is a revolutionary concept that changed how machines understand language. By
allowing each word to attend to every other word, it enables deep contextual understanding,
efficient computation, and superior performance.




