

Machine Learning often feels like a mysterious black box—data goes in, predictions come out. But in reality, it’s more like teaching a child using examples. The more quality data you provide, the better the system learns patterns and makes decisions.
If you’re a beginner, it’s important to start with algorithms that are not only powerful but also easy to understand. Let’s explore five fundamental machine learning algorithms in a simple and practical way.
Linear Regression
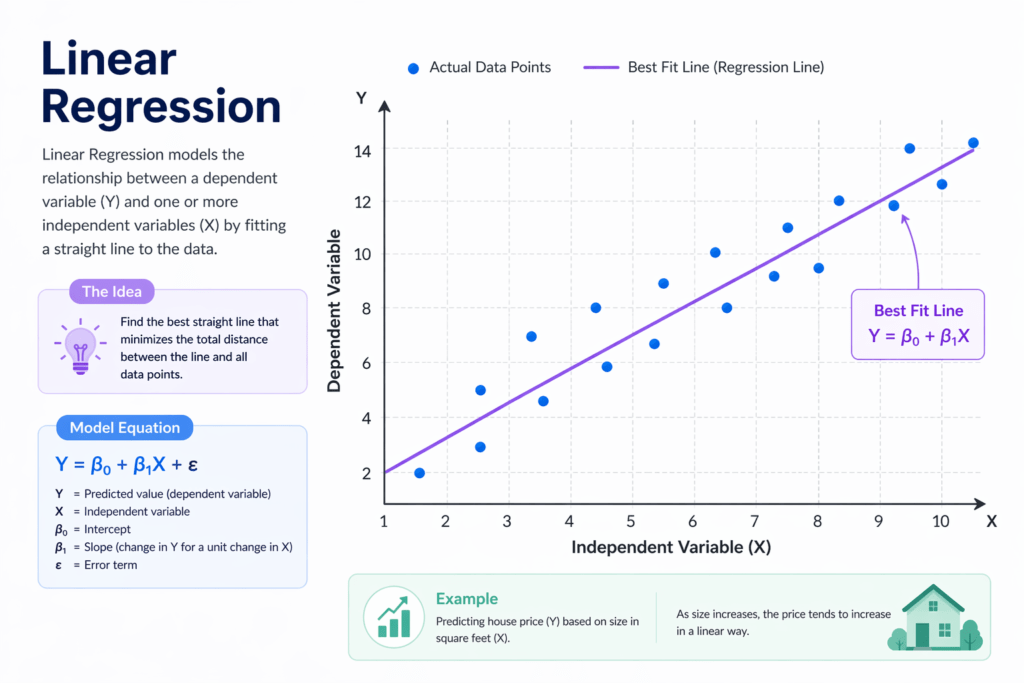
Linear Regression is one of the simplest and most widely used algorithms in machine learning. It is used to predict a continuous value based on the relationship between variables.
For example, imagine you want to predict the price of a house based on its size. Linear Regression draws a straight line that best fits the data points and uses that line to make predictions.
Where it is used:
- Predicting house prices
- Sales forecasting
- Temperature prediction
Why beginners should learn it:
It helps you understand how machines identify relationships between input and output. It’s the foundation for many advanced algorithms.
Logistic Regression
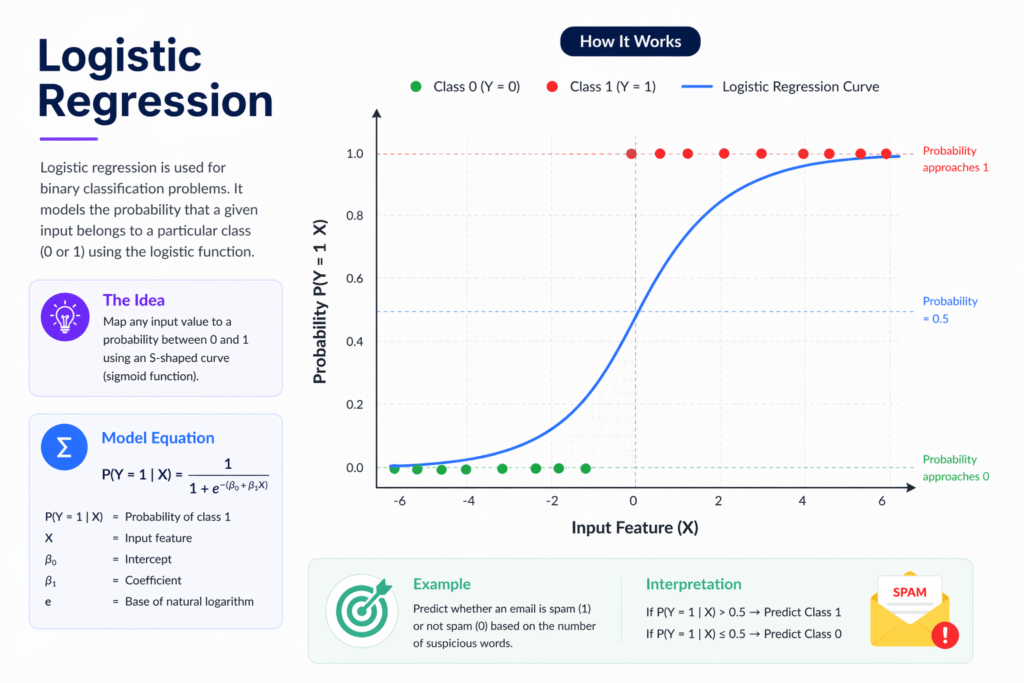
Despite its name, Logistic Regression is used for classification problems, not regression. It predicts the probability of an outcome that can have two categories, such as yes/no, true/false, or spam/not spam.
For example, an email system can use Logistic Regression to classify whether a message is spam or not.
Where it is used:
- Email spam detection
- Disease prediction (positive/negative)
- Customer churn prediction
Why beginners should learn it:
It introduces you to classification problems and probability concepts in a simple way.
Decision Trees
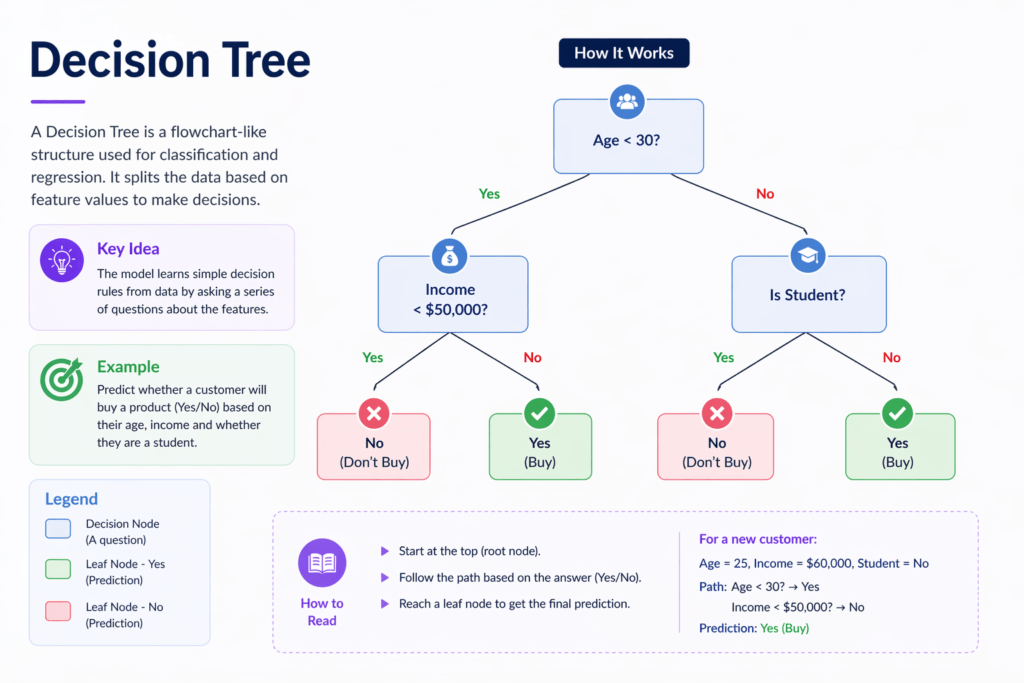
Decision Trees work like a flowchart. They split the data into branches based on different conditions, leading to a final decision.
For example, if you want to decide whether to play cricket:
- Is it sunny?
- Is it humid?
- Based on answers, you decide yes or no
Each question forms a branch, and the final answer is the outcome.
Where it is used:
- Loan approval systems
- Medical diagnosis
- Customer segmentation
Why beginners should learn it:
They are easy to visualize and understand. You can literally see how decisions are made step by step.
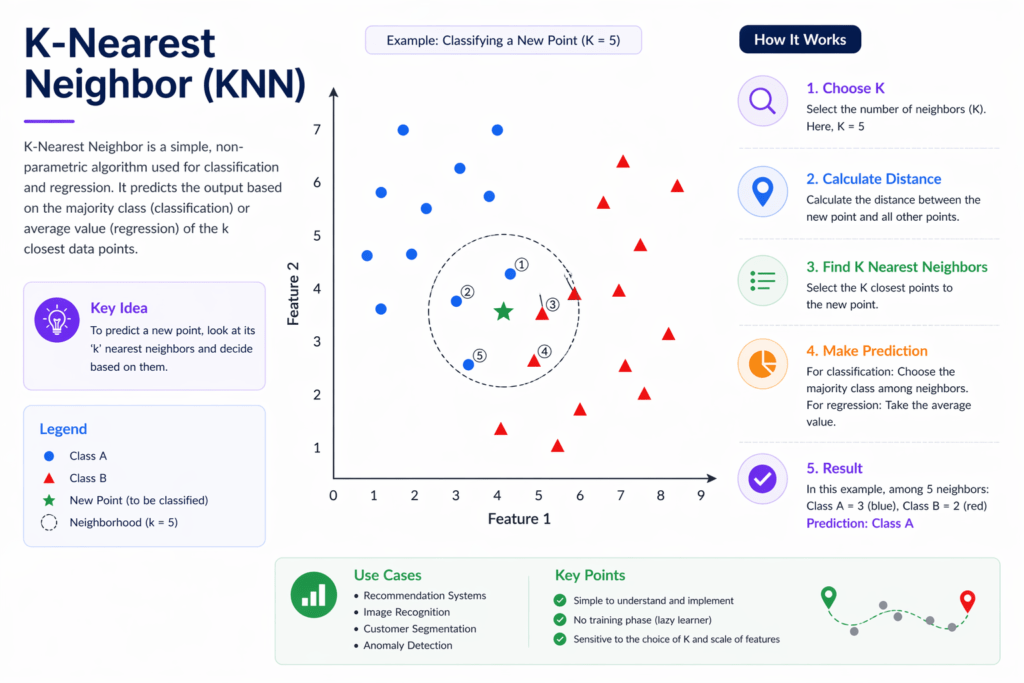
K-Nearest Neighbors (KNN)
KNN is one of the simplest algorithms. It classifies a data point based on how similar it is to its neighbors.
For example, if most of your closest friends like a certain movie, chances are you might like it too. KNN works in a similar way—it looks at the “nearest” data points and decides the category.
Where it is used:
- Recommendation systems
- Pattern recognition
- Image classification
Why beginners should learn it:
It builds intuition about how similarity and distance play a role in machine learning.
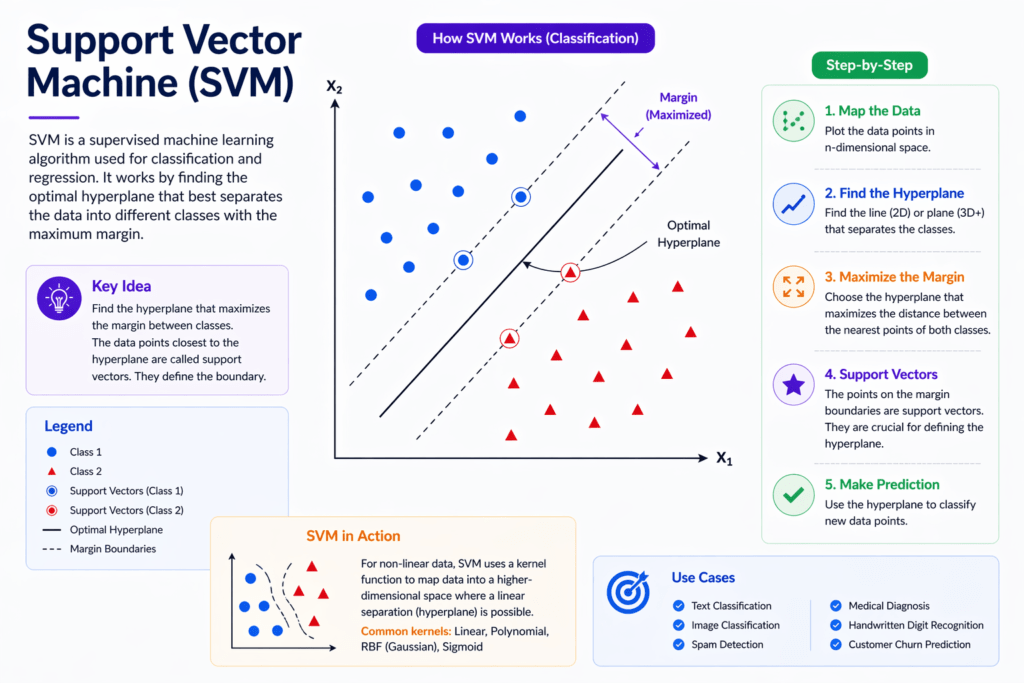
Support Vector Machine (SVM)
Support Vector Machine is a powerful algorithm used for classification. It works by finding the best boundary (called a hyperplane) that separates different classes of data.
For example, imagine separating apples and oranges on a table using a straight line. SVM tries to draw the line that creates the maximum gap between the two groups.
Where it is used:
- Face detection
- Text classification
- Bioinformatics
Why beginners should learn it:
It introduces the concept of margins and optimization, which are important in advanced machine learning.
Conclusion
Learning machine learning is like building a strong foundation for a house. These five algorithms are the building blocks that will help you understand more complex models in the future.
You don’t need to master everything at once. Start by understanding how each algorithm works, try simple examples, and gradually move to real-world projects.
Remember, consistency matters more than speed. The more you practice, the clearer everything becomes.




